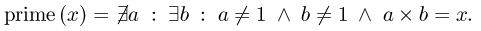
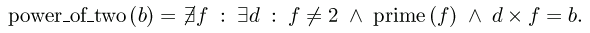
(See also the XHTML version, which has a better chance of showing you the MathML example, but also a better chance of not rendering at all.)
Not so long ago, my friend Sumana was trying to solve a problem from Gödel, Escher, Bach. Her friend Seth posted a possible solution on his weblog (scroll all the way to the bottom). I'm going to take advantage of this to rant about MathML, now that Mozilla supports it so I can test my examples.
The problem was to express the predicate "b is a power of two" using "typographical number theory," which is a limited form of mathematical logic. Here's how Hofstadter might have written Seth's solution, in his neatly typeset book:
Here's how Seth had to write it, in ASCII:
prime(x)
= not exists a
such that exists b
such that a!=1 and b!=1 and a*b=x.
power_of_two(b)
= not exists f
such that exists d
such that f!=2 and prime(f) and d*f=b.
Now the W3C has come up with a thing called MathML, which is supposed to allow us to write complex equations directly in HTML documents. Rendered in MathML, these definitions look something like this: (your browser probably doesn't support MathML, or has silly bugs; don't freak if it looks nothing like the neatly typeset version)
All very well and good, modulo the silly bugs. For instance, the
version of Mozilla I'm using to test the rendering with doesn't appear
to do any of the spacing right, even when bludgeoned with explicit
<mpadded> elements.
But wait, what does the source document look like? This:
<math> <mrow> <mi>prime</mi><mo>⁡</mo><mfenced><mi>x</mi></mfenced> <mo>=</mo> ∄<mi>a</mi><mo>:</mo>∃<mi>b</mi><mo>:</mo> <mi>a</mi><mo>≠</mo><mn>1</mn> <mpadded width="+30%"><mo>∧</mo></mpadded> <mi>b</mi><mo>≠</mo><mn>1</mn> <mpadded width="+30%"><mo>∧</mo></mpadded> <mi>a</mi><mo>×</mo><mi>b</mi> <mo>=</mo><mi>x</mi>. </mrow> <mrow> <mi>power_of_two</mi><mo>⁡</mo><mfenced><mi>b</mi></mfenced> <mo>=</mo> ∄<mi>f</mi><mo>:</mo>∃<mi>d</mi><mo>:</mo> <mi>f</mi><mo>≠</mo><mn>2</mn> <mpadded width="+30%"><mo>∧</mo></mpadded> <mi>prime</mi><mo>⁡</mo><mfenced><mi>f</mi></mfenced> <mpadded width="+30%"><mo>∧</mo></mpadded> <mi>d</mi><mo>×</mo><mi>f</mi> <mo>=</mo><mi>b</mi>. </mrow> </math>
Yes, I wrote that by hand. No, I never want to do it again. Presumably the W3C intended that people use automated editors to create this stuff, but I've not yet seen one, let alone one I'd want to use (it is easy to write an equation editor that looks nice but is bloody awful when you try to use it, as anyone who's tried to do serious math with Microsoft Word's equation editor will agree).
Is there an alternative? Yes; it's about twenty years old, widely used, easy to read, and generates much nicer output. It's called TeX, and I used it to create the neatly typeset version at the top of the page. This is the input:
$$
\func{prime}{x}
= \nexists a
\st \exists b
\st a \ne 1 \and b \ne 1 \and a \times b = x.
$$
$$
\func{power\_of\_two}{b}
= \nexists f
\st \exists d
\st f \ne 2 \and \func{prime}{f} \and d \times f = b.
$$
having previously defined some macros to deal with some nitty gritty details that it doesn't automatically handle:
\def\func#1#2{\hbox{#1}\,(#2)}
\def\and{\;\wedge\;}
\def\st{\;:\;}
\def\nexists{\raise0.1ex\hbox{$\not$}\kern0.1em\exists}
The source text is not much harder to read than the original plain
ASCII version Seth gave. I don't have to tell it that a
is a variable, 1 is a number, and × is an operator;
it already knows that. The macro definitions are arcane and
unpleasant to read, but they go up at the top of the document where
you can ignore them while you're writing. Furthermore, if I hadn't
bothered with them at all, the rendered output would still have come
out looking reasonably good.
So what's my point? you may be wondering. Fundamentally, this is a criticism of XML, and more generally of the current trend toward completely explicit markup languages. The argument is that by making the language utterly trivial to parse, we also make it easier to write software which processes it. So, no implicit markup, no macro language, no conveniences at all. That's nice as long as the only thing that ever generates marked-up text is a computer program; but that's not what's happening in real life. Plenty of people write HTML by hand; ditto DocBook and other XML-based languages.
The moment a notation stops being purely for computer use and starts being something that humans write to direct computers, the balance shifts. The purpose of computers, after all, is to make humans' lives easier. Therefore, when designing a notation for human use, the computer should be made to do as much grunt work as possible. It's okay if the parser is hard to write. After all, the parser only has to be written once; it can spit out one of these explicit representations which facilitates writing other programs to process it. I'd be perfectly happy if someone wrote a TeX back end that output MathML, for instance.
I'm also disappointed by the failure, of both the W3C and the Mozilla project team, to take advantage of a system which has existed for two decades and is known to solve the problem correctly. TeX's algorithms are thoroughly documented, its source code is freely available, and so are all its fonts. The W3C could have published reference rendering algorithms based on it. The Mozilla team could have appropriated and used the code. Yet Mozilla's rendering is visibly far worse.