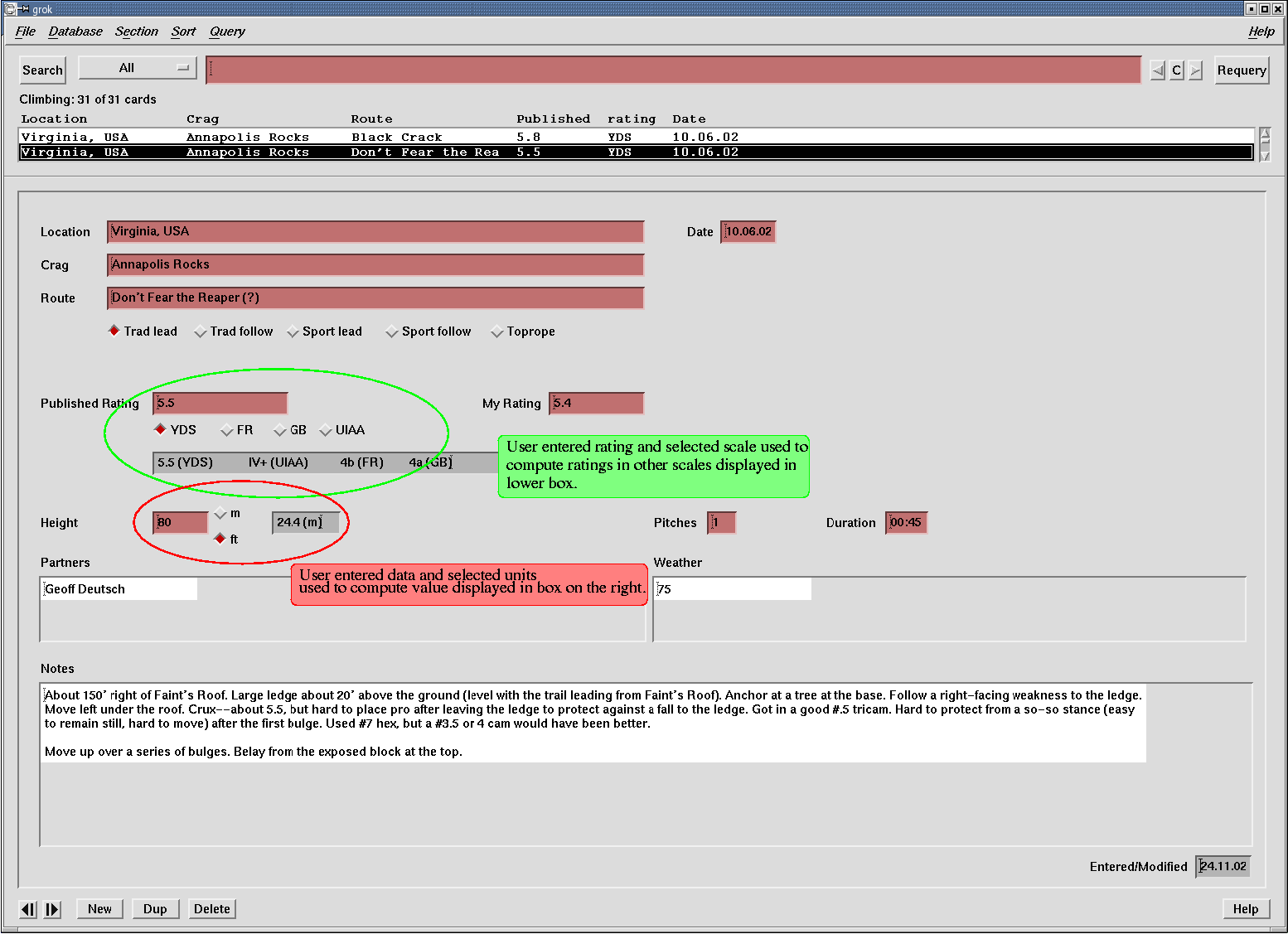
I've been looking for a good way to record data on my climbs. I've tried using eClimb for the Palm Pilot. It's nice, but it's hard to get a lot of text into the Pilot, and harder to get data out of eClimb.
Right now, I'm prototyping what I want my climbing database to really be by
using
I'm fairly happy with the data entry GUI and the fields, but
If you're interested, you can get a copy of the current database schema.
Here are some requirements:
- runs under *nix
- handles large plain text fields
- can call external programs (or has rich programming) to modify input
- full text searching across all fields
- Open source/GPL database platform (with easy installation, or pre-installed with common Linux distros). I really don't want to come up with a nice schema and data structures that depend on a database that's too complex for most people to install & maintain. Something that can be distributed as a self-contained application would be ideal.
- boolean seaches
Here are things that are NOT required:
- indices
- relational database
Finally, these things are on the "wish list" (in order of desireability):
- Windows version (using the same schema)
- Some way to store binary objects (photos, multimedia clips, etc.) with associated viewers (the viewer does not need to be integral to the database)
- command-line utilities for searching
- html output of searches of entire database
- web front-end
- plain text back end, or some back end that's mungable with tools like Perl (especially if there are existing CPAN libraries that know the DB format)
- multi-level searches (the ability to search on the results of a previous search)
- query-by-form
- GUI form builder
I think that "traditional" databases, such as mySQL, are overkill. Ideally, I'd like something where I can distribute the schema and database as a single archive for easy installation.
I started looking at Harbour (www.harbour-project.org). It's a cross platform, Open Source implementation of a compiler/environment for the Clipper language. I think it's more than I want (and the language is ugly ugly ugly, like some kind of C + Pascal hybrid), but it does offer the cross platform distribution I want.
Licensing issues, multiple platforms, low barriers to installation, etc. are important. I doubt that I'll have more than 500 records, and it's very hard to imagine anyone having more than 5000 records total. Each record (text) would probably be under 4KB, but I could see an upper bound of maybe 64KB/record if needed. Any binary data (BLOBs) would be treated separately.
Right now, my biggest concern is to find an appropriate platform before committing to more development.
[an error occurred while processing this directive]